Back_to_Directory 
AI Coding Developer Tools
oMLX
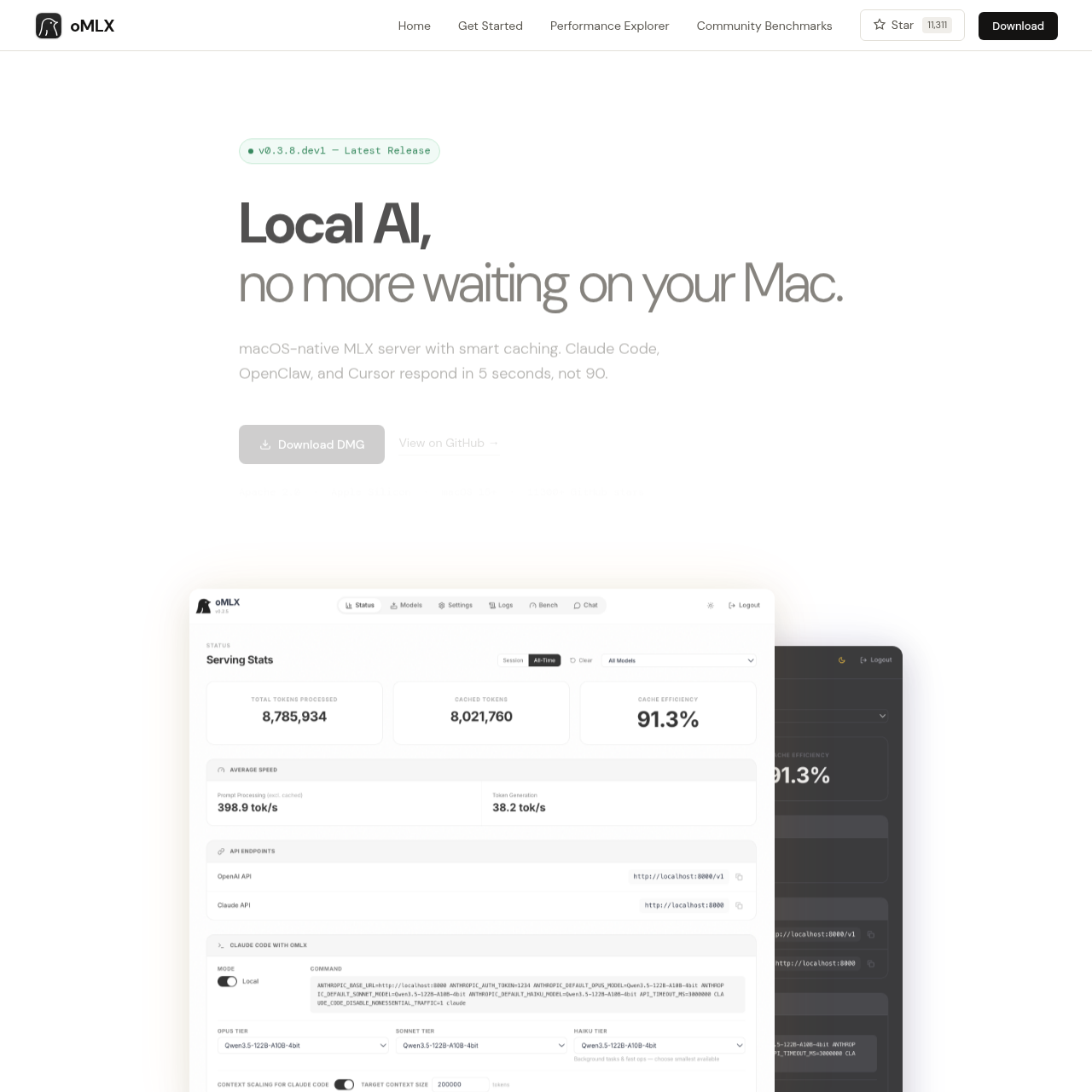
A native macOS inference server built on MLX. Paged SSD KV caching drops agent TTFT from 30-90s to under 5s. OpenAI & Anthropic compatible API for Apple Silicon.
Key Features
Paged SSD KV Caching
Persist cache blocks to SSD for faster recovery and reduced computation time.
Continuous Batching
Handles concurrent requests efficiently, improving generation speed.
Native macOS App
Manage the server from the menu bar with a web dashboard.
Multi-model Serving
Supports multiple models simultaneously with easy management.
OpenAI + Anthropic API Compatibility
Drop-in support for popular AI models and clients.
Use Cases
Local AI inference
Development of AI applications